Infinite Context in LLMs for Coding
The Hypothesis
yash101
Published 5/21/2026
Updated 5/23/2026

Image Generated using imgflip, inspired by Linus Torvalds
Are we misusing LLM context windows? How can we do more with smaller and cheaper models?
This started off as a hypothesis, but I built a prototype and tested it!
The Driver: humans ain’t the smartest. Yet…
We built:
- operating systems
- databases
- rockets
- compilers
All this, while our brains literally sip just 20 watts.
Yet, we’re talking about building terawatt-scale datacenters.
This was the elephant in the room which got me realizing that programming is not bottlenecked by raw intelligence or remembering everything. Instead, it’s a problem solved through:
- Navigation
- JIT context assembly and relying on our goldfish-style memory to forget unimportant details quickly
- Docs
- Search
- Notes
- Architecture patterns
LLM Context: the problem & flawed assumptions
Many modern coding agents treat codebases primarily as large collections of text to search and repeatedly summarize.
This creates an implicit assumption that code retrieval is mostly a text retrieval problem. I believe this assumption is incomplete and should be deleted.
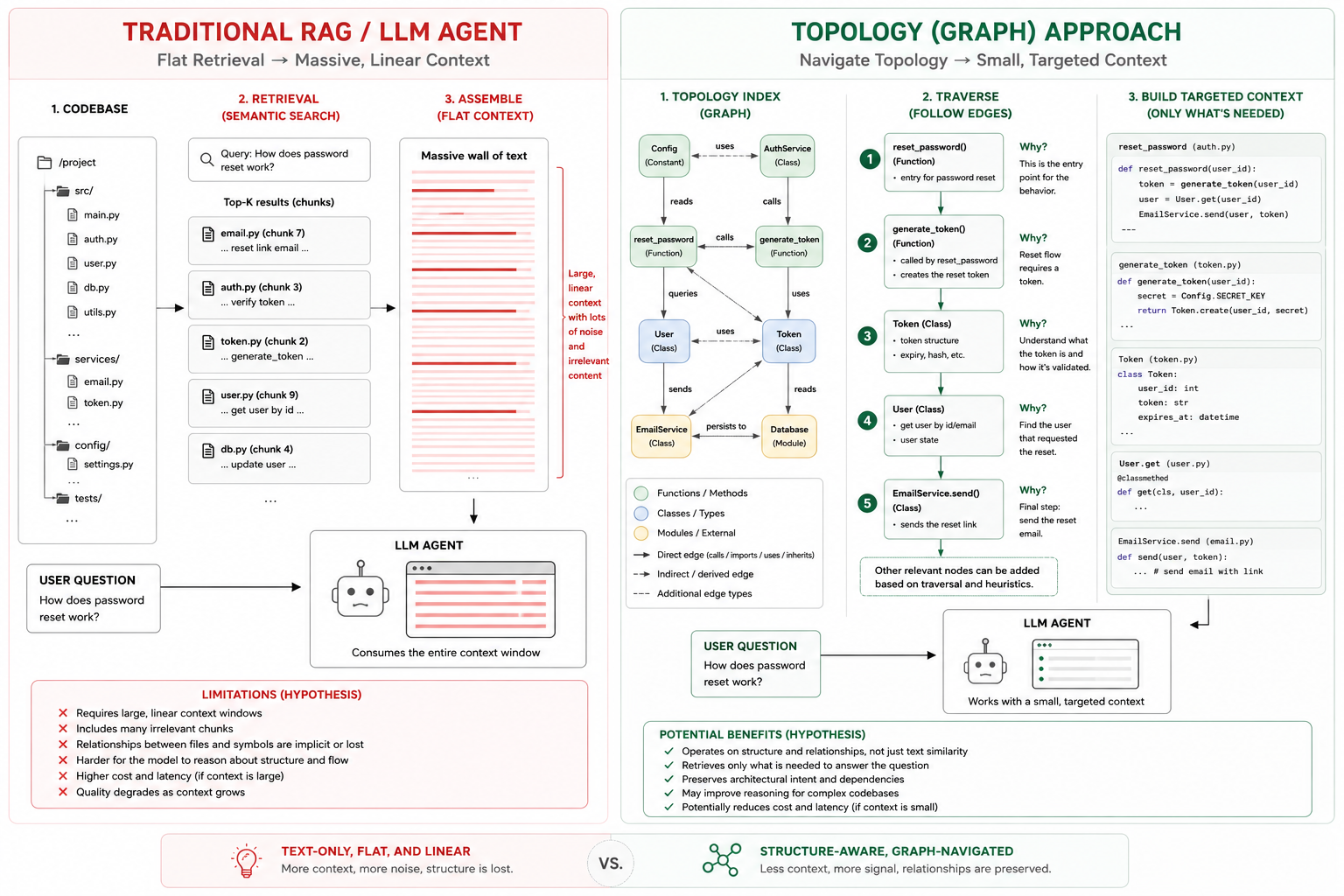
Image generated by ChatGPT as a visualization.
Topology & Locality
Code isn’t just a wall of text. Code is a directed graph of interconnected nodes
Most code today:
constants
functions
classes
constants
functions
classes
... this recurses
In distributed systems:
[A] -> [B] -> [C (external-facing API)]
|
V
[X]
Even in distributed systems, distributed connectivity is tightly defined and topology:
A:
class
function
apiClientB::hello_world()
fetch("/hello_world");
B:
class: Controller
[Route("/hello_world")]
function
return "leave me alone pls"
The structure becomes even more apparent at runtime:
- functionality rarely exists in isolation
- there is almost always a traversable path connecting behavior back to its origin
- A software without traversable topology has no behavior. It isn’t software.
- All software eventually manifests observable effects through connected execution paths
- Even prime95-esque or other “wasteful” software still show behavior such as power consumption, scheduling activity or thermal output.
The Hypothesis
LLMs don’t need inifinite context in codebases. They need the correct context.
Topology can be traversed to feed LLMs and agentic AI the context it needs more efficiently. I believe this would reduce the pressure for large context models and allow for smaller models to punch above their current capabilities.
How
- How
- Build tooling which hands LLMs the topology of the code so they don’t need to build it into their context
- Eventually
- Shrink context windows of LLMs and train the models to more efficiently navigate through the topology of code using these tools
Why?
- languages rely on strongly defined ASTs (abstract syntax trees) to navigate through code fast enough to compile or interpret code.
- the existence and widespread adoption of UML and related modeling systems
- literally exist specifically to represent topology in software and distributed systems.
- Though this argument is a bit of a chicken-and-the-egg.
There are real-life examples of this too:
- Clang (C/C++/ObjC/ObjC++) maskray.me
- v8 (js) v8.dev first party docs
Conclusion
Software is not just text. It is topology. It is connectivity. It is traversable structure.
Modern coding agents repeatedly reconstruct this structure through brute force context windows, summarization, and text retrieval. I believe this is the wrong abstraction layer.
We don’t memorize entire codebases. We navigate through them, with the help of our IDEs, docs, and understanding the architecture.
Compilers, interpreters, IDEs, static analyzers, and linkers already rely heavily on the fact that software is structured and machine traversable. Modern coding agents should too.
This started off with me facing the pain of being too broke to afford Opus 4.7 in Claude Code. Then it turned into a hypothesis:
What if smaller and cheaper models could become significantly more capable simply by navigating software topology more efficiently?
So I built a prototype.
In the next article, I’ll cover:
- topology extraction
- graph indexing
- why I chose LMDB
- where the prototype failed
- and what happened when I tried this against a real codebase
What’s Next
This article, to me, is funny because it started with me being too broke to afford Claude Opus 4.7 (if ur anthropic free tokens pretty pls?).
As it turns out, I’m further along on this journey than this article suggests. However, I have a startup to tend to, and I prefer to write high quality content and that takes a lot of time and energy.
What I ultimately learned through building and breaking this prototype completely flipped my understanding of AI systems engineering on its head:
Retrieval is only 30% of the problem. The rest is ranking and prioritization
The core hypothesis still stands: LLMs don’t need inifinite context in codebases. They need the correct context..
Over the upcoming articles, I’ll document exactly how I built a multi-index architecture to tackle this, and where my original assumptions shattered:
- The Foundation: mapping topology and making it searchable without a graph-native database
- The Friction: where pure topology wins and where it falls on its face
- The Pivot: building a hybrid architecture to address the shortcomings
- The Latent Reality: high-dimensional embeddings natively encode some level of topology